
https://papers.nips.cc/paper_files/paper/2014/hash/35051070e572e47d2c26c241ab88307f-Abstract.html
これも東大杉山研じゃないか、たまげたな。
前にやったPU Learningは、強い分布に対しての仮定が必要だった。つまり、PositiveなDataのうちから一様に抽出して、ラベル付きになっているという強い分布への仮定が必要だった。今回のやつはそこへのカウンターも兼ねた理論的な証明。
問題設定
Positive(+1)とNegative(-1)の誤分類を最小化する関数は以下のように書ける。これは、誤分類の割合を表す関数。
まず、あるデータについて、ラベル付けする識別器があるとする。また、
- 本来Negative=-1なのに、識別器にPositive=1に分類されてしまう確率。
- 本来Positive=1なのに、識別器にNegative=-1に分類されてしまう確率
- は全sampleのうちのpositiveの割合であり、で推定する。
なお、01損失を使っている以上、この損失は誤り率そのものである。
また、ここから更にcost-sensitive=重み付き分類は、上記の式にcostのc_1, c_{-1}をつけたもの。これは以下のもの。結局後述するCost-SensitiveなPUの式は、このようなPN分類の重み付きに帰着できるよ。
PU分類
上の式はPositive=1とNegative=-1だったが、PU分類ではUnknownにNegativeが全部入ってるし、Positiveも一部ある。は前述のとおり、全sampleでのPositiveな割合。(Positiveなラベルしかつけないというけどさすがにsampleを見る限りNegativeが何個あったかも把握はしておくので、が求まる。これがラベルなしのデータでも同じ割合であると推定)この時、↓の式のように、ラベル付けされてないものの確率を求めることができる。
次に、=分類器f(X)が、P_Xに対してその中でPositiveの確率として、求めてみる。つまりでは?と思うが、は全体のPositiveな真の割合であり、は推定してるといえる。
これ、ある訓練データから一部をPositiveとしてラベル付けしておくかたちだが、多分ラベルなしは、訓練データでのNegativeを除く。排除しないと、割合がで推定できないから(Negativeが予想以上に混入するので)。
となる。ここで、を使った。これは、Positiveデータにおいて、Positiveであると正解する確率は、余事象として1からPositiveデータにおいてNegativeデータであると正解する確率を引いたものに等しいから(二値分類なので)
後続研究ではこの代入を使わずに、そのままに直さずに解いて、に着目した。この論文では後述するように、この代入をすることで、に着目している。
📄![]() 2015-ICML-[uPU] Convex Formulation for Learning from Positive and Unlabeled Data
2015-ICML-[uPU] Convex Formulation for Learning from Positive and Unlabeled Data
この、ラベルなしのクラスのうち、識別器にpositiveと認識される確率であるだが、これを使っても表してみる。なんせPU分類にはは分からないから、できるだけ消したい。重みは一旦なしで見る。
そして、をに対してが占める割合とする。今まではで、Negativeも入れた中でのSampleのPositiveの割合だった。
しかし、は、ラベル付き=Positiveとラベルなし(Negativeの割合は使わない!)ということ。
このという量を使って、を無理やり式変形してみる。
このように、はじめにいった重み付きのPN分類に帰着できるとわかるね。
実用的な話は上のを最小化するで終わっていて、これは帰着できるというだけの話である。その帰着の過程で、Unlabeledの損失はNegative例の扱いである。
損失関数について
ここで定める損失関数は正解=正であるほど小さい値をとって、不正解ほど大きな値をとる。
ヒンジ損失関数を考える。=ReLU関数。
ランプ損失関数を考える。
PN分類における損失の違い
PN分類では、Ramp損失のほうが使われず、Hinge損失を基本的に使う。
理由としては、
- 分離可能性。損失の和が0なら、すべてのサンプルにおいて損失が0。これは両方の損失で成り立つ。
- サンプルが分離可能である場合、Ramp損失で0になるならHinge損失でも0になる。なので、最適化しやすいHinge損失のほうがやっぱりいい。
- Hinge損失は凸関数である。凸関数の合成となると最適化しやすい。
- Hinge損失は-1を下回っても傾きは-1であるが、Ramp損失は-1を下回ると傾きは0になって、+1以上特別がつかなくなり学習に一部支障が出るようになる。
- なお、この一部の区間以外の傾きを0にするのはカットオフである。
PU分類ではRamp損失のほうがいい
Ramp損失は左右対称なので、以下の式が成り立つ。
PU分類の損失の式を分解すると以下のようになる。
ここで、Ramp損失なら前の項が定数なので、実際の最適化で考慮しなくていい。Hinge損失なら考慮することになり、最適化の項が増えて結果的に難しくなる。
つまり、凸だから最適化しやすい以上に、項が増えることによって実際の最適化が難しくなってしまうということ。
実演
中心-3, 分散1をPositive、中心+3, 分散1をNegativeとする。この一次元データを線形分類器で、異なるclass priorで分類すると考える。これは大体かぶってない。
この時、以下のようになってしまう。
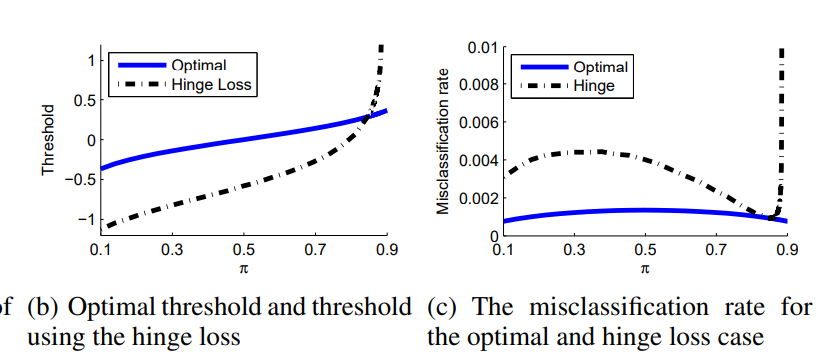
Ramp損失はOptimalの青い線と全く同じになるらしい。
このようにHinge損失で実際に最適化するとなかなかうまくいかないとわかる。
つまり、実際の最適はではの最小化をするが、結果的にキャンセルできるRamp損失を使うと計算するうえで性能が良くなるということ。
Class Priorの推定
を推定することが重要。間違った推定がどれほどの影響をもたらすかを考察する。
01損失については、という式になる。この時が0か1の時損失は必ず0になる。それ以外では分離可能ではない限り、ふっくらとした以下のような凸関数になる。
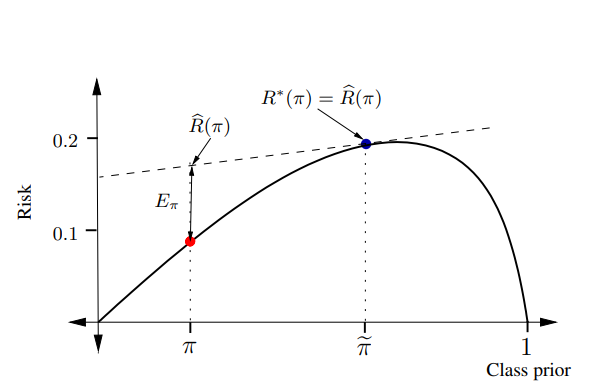
この中で、我々が限られたデータから学習できるのはであり、これが実線のと等しいのが望ましい。
これがPUになると、推測されたから以下の式の最小化になる。
ここで、推測したはの内部の組成に関係はないため、のままである。これを意識して式変形すると以下のようになる。
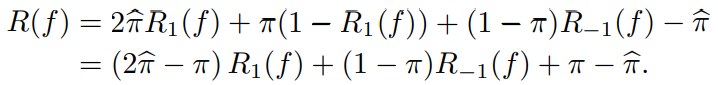
の係数が正である必要があるので、悪くともである必要がある(高く推測しすぎてはだめ)
さらに、以下のようにを定義する。これは上のの係数を正規化したもの。
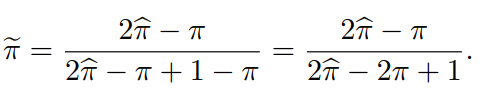
結果としては以下の式になる。
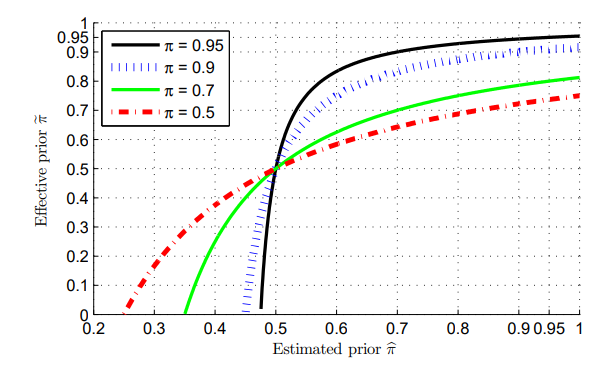
が十分に大きければ、推測するClass Priorが大きく変わっても、損失関数の最小化をするときにかかっている係数から見れば大して変わらないということ。
PU分類の誤差 in 同一分布じゃない
注意:他の論文を読んでたら、ここでは前提として「Positiveでラベル付けされてるものとされてないものは同じ分布に従う」とあるらしい。じゃあこれはなんだ...?
PU分類は、同一分布に従う必要がある。つまり、ラベル付けでPositiveになってるのは、Positive全体のデータからランダムに抽出させないとアカン。
では、同一分布に従ってない時(=ランダムに抽出してない?)はどうする?その時の誤差はどうなるのか、を解析したのがこの論文。
関数を次のように定める。
- は実数。
- 。Positiveの分布に従い、ランダムに\mathbf{x}_iをn個抽出した。
- 。つまり、これはPositive、Negative関係なくランダムにを個抽出した。
つまり、n個のPositiveと、個のラベルなしがあるとして、それらと引数のカーネル内積の一定係数の線形結合。この関数での誤差を考えてみる。
これをごにょごにょすると(中略...)
一定分布に従わないという最悪な状況でも、誤差は
のオーダーになる。これは個が独立同分布に従って得られ、個がまた別の独立同分布に従ってる場合に最適である。
もし、いずれも同じ独立同分布に従ってるなら、
だが、これは非現実的。同じ独立同分布に従ってるなら、PU Learningする意味ないので。
ただ、これを見る限り、どれほど分布が違っていようが、完全に一致の分布からとを取ってるのと比べて、たかだか倍までしか悪くならない!